本文为知乎版本的纠错和 markdown 版本 在学习深度学习相关知识,无疑都是从神经网络开始入手,在神经网络对参数的学习算法bp算法,接触了很多次,每一次查找资料学习,都有着似懂非懂的感觉,这次趁着思路比较清楚,也为了能够让一些像我一样疲于各种查找资料,却依然懵懵懂懂的孩子们理解,参考了梁斌老师的博客BP算法浅谈(Error Back-propagation)(为了验证梁老师的结果和自己是否正确,自己python实现的初始数据和梁老师定义为一样!),进行了梳理和python代码实现,一步一步的帮助大家理解bp算法!
为了方便起见,这里我定义了三层网络,输入层(第0层),隐藏层(第1层),输出层(第二层)。并且每个结点没有偏置(有偏置原理完全一样),激活函数为sigmod函数(不同的激活函数,求导不同),符号说明如下:
| Wab | 代表的是结点 a 点结点 b 的权重 |
|---|
| ya | 代表结点 a 的输出值 |
| za | 代表结点 a 的输入值 |
| δa | 代表结点 a 的错误(反向传播用到) |
| C | 最终损失函数 |
| f(x)=1+e−x1 | 结点的激活函数 |
| W2 | 左边字母, 右边数字, 代表第几层的矩阵或者向量 |
对应的网络如下:
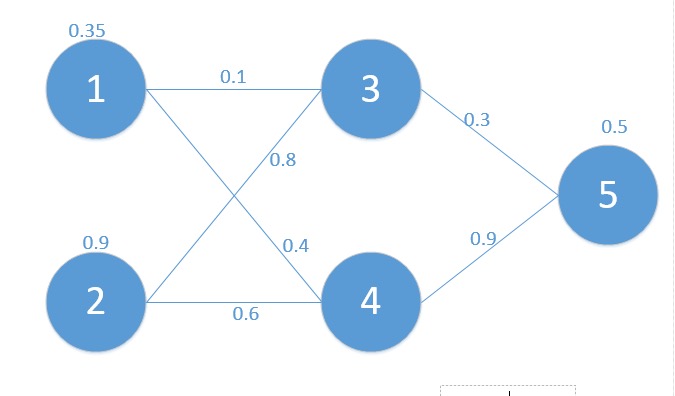
其中对应的矩阵表示如下:
X=Z0=[0.350.9]
yout=0.5
W0=[w31w41w32w42]=[0.10.40.80.6]
W1=[w53w54]=[0.30.9]
首先我们先走一遍正向传播, 公式与相应的数据对应如下:
z1=[z3z4]=W0×X=[w31w41w32w42]×[x1x2]=[w31×x1+w32×x2w41×x1+w42×x2]=[0.1×0.35+0.8×0.90.4×0.35+0.6×0.9]=[0.7550.68]
那么:
y1=[y3y4]=f(W0×X)=f([w31w41w32w42]×[x1x2])=f([w31×x1+w32×x2w41×x1+w42×x2])=f([0.7550.68])=[0.6800.663]
同理可以得到:
z2=w1×y1=[w53w54]×[y3y4]=[w53×y3+w54×y4]=[0.801]
y2=f(z2)=f(w1×y1)=f([w53w54]×[y3y4])=f([w53×y3+w54×y4])=f([0.801])=[0.690]
那么最终的损失为:
C=21(0.690−0.5)2=0.01805
这也就是我们的目标函数, 我们的目标就是通过调整权重矩阵W0和W1, 让损失函数C最小! 这里用的方法就是梯度下降法, 接下来看看如何进行反向传播
⎩⎨⎧Cy2z2=21(y2−yout)=f(z2)=(w53⋅y3+w54⋅y4)
那么我们可以通过链式法则, 求出损失函数C对w53的偏导数:
∂w53∂C=∂y5∂C⋅∂z5∂y5⋅∂w53∂z5=(y5−yout)⋅f′(z2)⋅(1−f(z2))⋅y3=(0.69−0.5)⋅(0.69)⋅(1−0.69)⋅0.68=0.02763
其中 sigmod 函数的导数为:
f(x)f′(x)=1+e−x1=−(1+e−x1)2⋅(−e−x)=1+e−x1⋅(1−1+e−x1)=f(x)⋅(1−f(x))
同理可得:
∂w54∂C=∂y5∂C⋅∂z5∂y5⋅∂w53∂z5=(y5−yout)⋅f(z5)⋅(1−f(z5))⋅y4=(0.69−0.5)⋅(0.69)⋅(1−0.69)⋅0.663=0.02711
现在我们继续求其他的偏导数
W31,W32,W41,W42
给出其中一个的求导过程, 其他的类似
⎩⎨⎧Cy5z5y3z3=21(y5−yout)2=f(z5)=(w53∗y3+w54∗y4)=f(z3)=w31∗x1+w32∗x2
∂w31∂C=∂y5∂C∗∂z5∂y5∗∂y3∂z5∗∂z3∂y3∗∂w31∂z3=(y5−yout)∗f(z5)∗(1−f(z5))∗w53∗f(z3)∗(1−f(z3))∗x1
最终的结果为:
⎩⎨⎧w31w32w41w42=w31−∂w31∂C=0.09661944=w32−∂w32∂C=0.78985831=w41−∂w41∂C=0.39661944=w42−∂w42∂C=0.58985831
