
go gmp流程
本文是对 小徐先生 的 gmp 原理解析的一些阅读笔记
为什么要引入 gmp
在协程之前, 采用的是线程模型, 线程也是操作系统对应的最小调度单元, 但是线程对于一些任务来说还是太重了
创建一个新的线程, 操作系统会分配一个 8MB 的栈空间, 而且线程之间的切换也都要从用户态切换到内核态, 代价比较高
于是 很多语言引入了协程的概念, 协程是用户态的轻量级线程, 由用户自己调度, 代价比较小, 也不需要分配那么大的栈空间
coroutine 在 python 的实现由该协程主动交出控制权, 这种方式让用户比操作线程有更多的控制权, 但是也要求用户对自己的代码负责, 不能阻塞协程
go 则是对 coroutine 做了一定的改动, 由 go 来分配协程之前的调度, 更加像一个线程了.
gmp 模型
goroutine 的强依赖于 go 设计的 gmp 模型的
gmp 分别是
- g : goroutine, 代表一个协程
- m : machine, 代表一个操作系统线程
- p : processor, 代表一个逻辑处理器, 负责调度 g 到 m 上运行
[!NOTE]
可以说 go 完全屏蔽了线程的概念, 让用户的操作都以 g 为粒度, 统一了并发操作
g
g 代表 go 中的 协程, 有自己的运行栈,生命周期和执行任务函数
g 一定要绑定到 m 上执行
m
m 是 go 中对线程的一个抽象, m 要和 p 绑定后才能执行 g
m 中有一个 g0, 这就是对 g 的一个抽象, 用来找任务, 然后执行 g
p
p processor, 是 golang 中的调度器
p 为 m 到执行代理, m 要与 p 绑定后, 才会进入到调度中; 因此 p 的数量决定了 g 的最大并行数量(由 GOMAXPROCS 控制, 默认等于 CPU 核心数)
p 自带了一个本地 g 队列, 用来存放等待被调度的 g 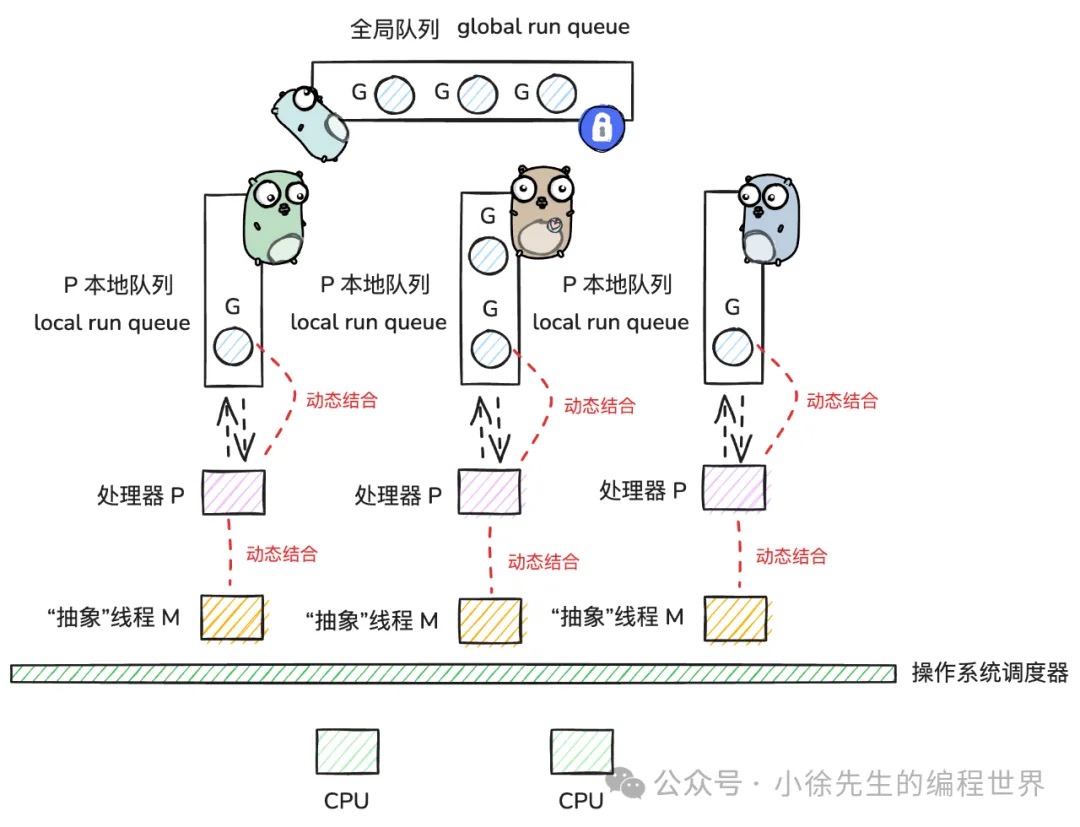
g 内部有一个本地队列 lrq ( local run queue ), 用来存放本地的 g, 有一个本地队列的好处是减少了竞争 但也并不是一个完全的并发, 因为还有偷取功能, 导致并不能完全没有竞争
其次有一个全局队列, 当某个 lrq 不满足条件时, 会从全局队列中获取 g,
put and get
put g: 当一个 g 被创建时, 会先放到 p 的 lrq 中, 如果 lrq 满了, 会放到全局队列中
get g: 当 m 与 p 结合后, g0 会不断的找合适的 g 用来执行, 此时会采取 "负载" 均衡的方式来获取 g
- 优先从当前 p 的 lrq 中获取 g
- 从全局队列中获取 g
- 取 io 就绪的 g (netpoll)
- 从其他 p 的 lrq 中偷取 g
注
g0 在每 61 次出席的时候, 会尝试从全局队列中获取 g, 以防止 lrq 中 g 太多, grq 饥饿
gmp 数据结构
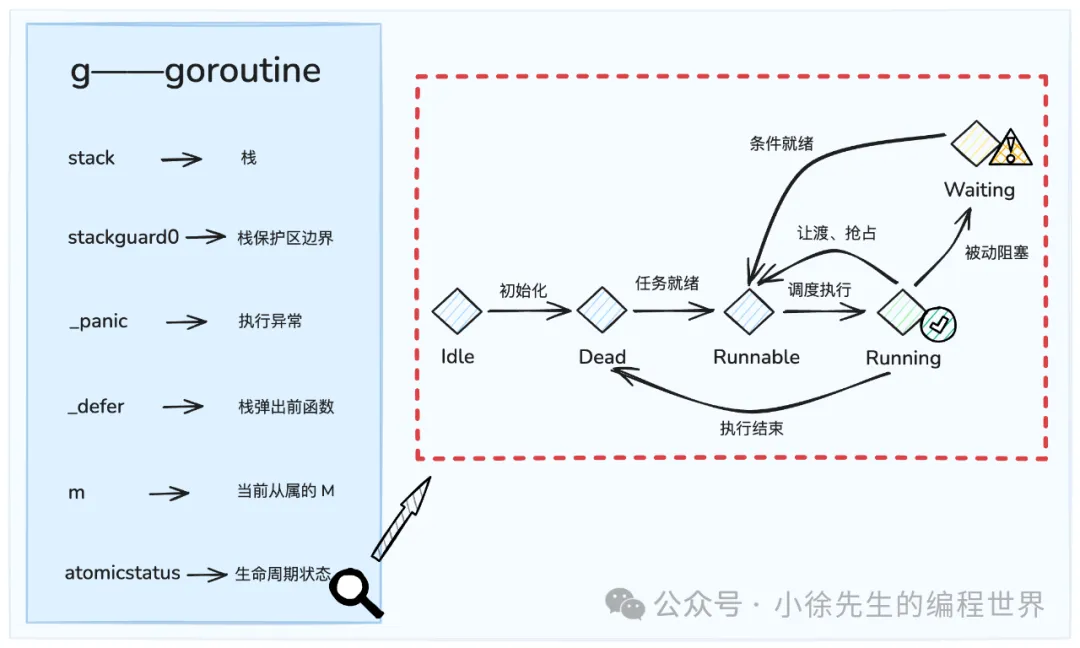
type g struct {
stack stack // 运行栈
stackguard0 uintptr // 栈保护
_panic *_panic // 当前 panic
_defer *_defer // defer 列表
m *m // 绑定的 m
atomicstatus uint32 // g 的生命状态
}其中要注意的几个参数
stackguard0: 这是栈保护区的边界, 也是用来传递抢占标识的 比如当前的 goroutine 不该运行了, 那么会在这个边界上设置一个抢占标识, 当 这个 goroutine 的栈进行扩充时, 检测到了这个标识, 就会自己让出 CPU, 不过这是主动的, 被动的还有一些不一样
defer: 创建的 defer 链表
m 当前的执行 g 的 m
一个 goroutine 有五个状态, 分别是 Idle, Dead, Runnable, Running, Waiting, 其流转如图
m 详设
m 为 go 对线程的抽象, 其核心成员为
- g0: 特殊的 g, 不由用户创建, 与 m 为一对一的
- gsignal: 用来处理信号的 g
- curg: 当前正在执行的 g
- p: 与m绑定的 p
m 的运行目标为 g0 和 g, 两者交替进行;g0 的作用是用来寻找需要执行的 g, g 是 g0 找到并分配给 m 执行的任务
p 详设
p 是 gmp 的调度器, 其核心成员为
- status: p 生命周期状态
- m: 当前和 p 结合的 m
- runq: p 私有的 g 队列 - local run queue(lrq)
- runqhead: lrq 中队首的节点的索引
- runqtail: lrq 中队尾节点的索引
- runnext: lrq 中的特定席, 指向下一个要执行的 g
type p struct{
id int32
/*
p 的状态
// p 因缺少 g 而进入空闲模式,此时会被添加到全局的 idle p 队列中
_Pidle = iota // 0
// p 正在运行中,被 m 所持有,可能在运行普通 g,也可能在运行 g0
_Prunning // 1
// p 所关联的 m 正在执行系统调用. 此时 p 可能被窃取并与其他 m 关联
_Psyscall // 2
// p 已被终止
_Pdead // 4
*/
status uint32// one of pidle/prunning/...
// 进入 schedt pidle 链表时指向相邻 p 的 next 指针
link puintptr
// ...
// p 所关联的 m. 若 p 为 idle 状态,可能为 nil
m muintptr // back-link to associated m (nil if idle)
// lrq 的队首
runqhead uint32
// lrq 的队尾
runqtail uint32
// q 的本地 g 队列——lrq
runq [256]guintptr
// 下一个调度的 g. 可以理解为 lrq 中的特等席
runnext guintptr
// ...
}schedt 详设
schedt 是全局的资源模块, 在访问前要加全局锁
- lock: 全局的互斥锁
- midle: 空闲 m 队列
- pidle: 空闲 p 队列
- runq: 全局 g 队列 global run queue(grq) -runqsize: grq 中存在的 g 数量
// 全局调度模块
type schedt struct{
// ...
// 互斥锁
lock mutex
// 空闲 m 队列
midle muintptr // idle m's waiting for work
// ...
// 空闲 p 队列
pidle puintptr // idle p's
// ...
// 全局 g 队列——grq
runq gQueue
// grq 中存量 g 的个数
runqsize int32
// ...
}注
之所以存在 midle 和 pidle 的设计, 是为了避免 p 和 m 因为缺少 g 而导致 cpu 空转 对于空闲的 p 和 m, 会被集成到空闲队列中, 并且会暂停 m 的运行
调度原理
main 函数
文中说这是一个特殊的, 由全局唯一的 m0 来执行, 但并不是很懂有什么用
g 的调度
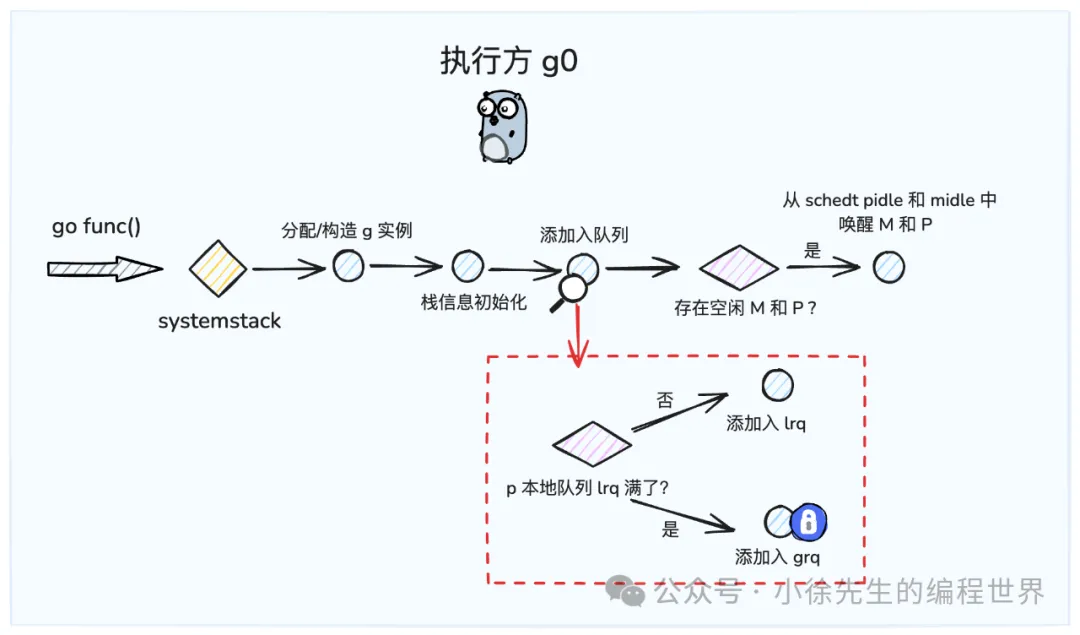
用户通过 go func 创建的 goroutine, 都会以 g 的形式进入到 gmp 中
加入的顺序为
- 如果当前的 p 的 lrq 没有满, 则放入 lrq 中
- 否则放入全局的 grq 中(这里要加锁)
// 创建一个新的 g, 入参为用户的函数 fn
// 当前执行的是一个普通的 g
func newproc(fn *funcval) {
// 获取当前正在执行的普通 g 及 程序计数器 pc (program counter)
gp := getg()
pc := sys.GetCallerPC()
// systemstack 会临时切换到 g0 来执行, 当执行完毕后, 切换回原 g
systemstack(func() {
// 这里相比 1.9 版本, 多了 false 和 waitReasonZero 两个参数
// false 表示这个 g 不是系统 g
// waitReasonZero 表示这个 g 没有特殊的等待原因
newg := newproc1(fn, gp, pc, false, waitReasonZero)
//获取当前的p
pp := getg().m.p.ptr()
runqput(pp, newg, true)
// 如果存在因过度空闲而被 block 的 p 和 m,则需要对其进行唤醒
if mainStarted {
wakep()
}
})
}其核心的 runqput 为
// 将 gp 放入 pp 的本地运行队列中
// 如果 next 为 true, 则将 gp 放入 runnext 特等席中
// 如果 lrq 满了, 则放入全局 grq 中
func runqput(pp *p, gp *g, next bool) {
if !haveSysmon && next {
// runnext goroutine 和当前的 goroutine 共享同一个时间片
// 这是为了 A->B->A 这种切换导致其他的 goroutine 饥饿
next = false
}
if randomizeScheduler && next && randn(2) == 0 {
next = false
}
if next {
retryNext:
oldnext := pp.runnext
if !pp.runnext.cas(oldnext, guintptr(unsafe.Pointer(gp))) {
goto retryNext
}
if oldnext == 0 {
return
}
// Kick the old runnext out to the regular run queue.
gp = oldnext.ptr()
}
retry:
h := atomic.LoadAcq(&pp.runqhead) // load-acquire, synchronize with consumers
t := pp.runqtail
// 如果没有满的话, 放入到末尾
if t-h < uint32(len(pp.runq)) {
pp.runq[t%uint32(len(pp.runq))].set(gp)
atomic.StoreRel(&pp.runqtail, t+1) // store-release, makes the item available for consumption
return
}
// 这会把 g 和 一半的 lrq 中的 g 一起放入到全局 grq 中
if runqputslow(pp, gp, h, t) {
return
}
// the queue is not full, now the put above must succeed
goto retry
}几个要注意的点
- CAS 操作, 这是一个原子操作, 用来把两个值进行比较, 如果相等则赋值
g0 和 g 之间的调度
在每个 m 中会有一个与之伴生的 g0,其任务就是不断寻找可执行的 g. 所以对一个 m 来说,其运行周期就是处在 g0 与 g 之间轮换交替的过程中.
在 m 运行中,能够通过几个桩方法实现 g0 与 g 之间执行权的切换:
g -> g0:mcall、systemstack
g0 -> g:gogo
// 从 g 切换至 g0 执行. 只允许在 g 中调用
func mcall(fn func(*g))
// 在普通 g 中调用时,会切换至 g0 压栈执行 fn,执行完成后切回到 g
func systemstack(fn func())
// 从 g0 切换至 g 执行. gobuf 包含 g 运行上下文信息
func gogo(buf *gobuf)go 执行两个核心方法来切换到 g
- schedule: 调用 findRunnable 方法,获取到可执行的 g
- exexute: 更新 g 的上下文信息, 调用 gogo 方法, 将 m 的执行权从 go 切换到 g
抢占设计
go 语言对协程的改进就在于引入了抢占式调度, 也就是说 g 不再是完全主动交出控制权的
监控线程
在 go 程序运行时,会启动一个全局唯一的监控线程——sysmon thread,其负责定时执行监控工作,主要包括:
- 执行 netpoll 操作,唤醒 io 就绪的 g
- 执行 retake 操作,对运行时间过长的 g 执行抢占操作
- 执行 gcTrigger 操作,探测是否需要发起新的 gc 轮次
系统调用
当一个 g 进入系统调用时, 会把当前的 p 与 m 分离, 让出 p 给其他的 m 使用
系统调用的时候, 线程没有能力去自己切换, 所以要把 p 让出来
运行超时
当有一个 g 运行超过了 10ms, sysmon 会设置该 g 的抢占标识, 让其在下次栈扩充时, 主动交出控制权
go 1.14 之后, 引入了异步抢占的设计, 也就是说不需要等到栈扩充时才抢占, 而是直接通过修改 pc 寄存器的值, 改变了 g 的下一个指令, 来让 g 进入调度状态